1. Understanding concept of Decision Tree
Decision Tree is a popular and easy-to-understand machine learning algorithm. It is accessible and can be applied to solve both classification and regression problems. The mechanism of a decision tree is to form a sequence of classification rules based on the values of features in order to decide which outcome will be assigned to the target variable. Although it is simple, care must still be taken to prevent overfitting and ensure the model can generalize well to new data.
But ..what makes the Decision Tree easy to understand for people who are even just starting their machine learning journey? Let’s examine the basic structure of a decision tree and an example.
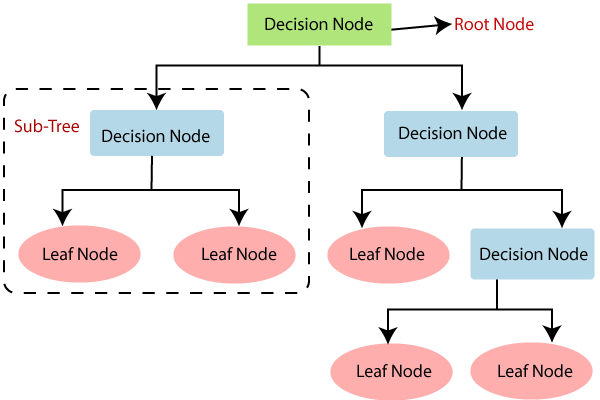
-
- Root Node: This is the topmost node, representing the entire dataset. From this node, the data is split into two or more homogeneous subsets.
-
- Decision Nodes: Also referred to as internal nodes in some references. These are the nodes where the data is split based on a specific criterion.
-
- Leaf Node: These nodes represent the final output (classification or decision) and cannot be split any further.
One of the reasons why the Decision Tree algorithm is easy to understand is that it closely resembles rule-based analysis. In other words, we often classify data by setting conditions—if the data meets the condition for Group A, it is assigned to Group A, and similarly for other groups. The difference here is that, in rule-based analysis, the classification conditions are defined manually by humans, based on experience or specific requirements.
In decision tree algorithms, the process of setting classification conditions is based on scanning all observations and features to calculate a certain metric (which will be discussed later). This measure helps determine the most important features to be used as decision nodes, along with the conditions at these nodes to classify which observations should be assigned to which leaf nodes.
We’ll illustrate the process with a lung cancer example:
Disclaimer: The example provided is solely for the purpose of understanding the concept of models and is not intended for use in actual medical diagnosis or treatment.
This dataset contains multiple observations of individuals who either have lung cancer or do not. Each individual provided information about their lifestyle habits and biological characteristics, such as gender, age, smoking status, anxiety levels, presence of chronic diseases, alcohol consumption, coughing, shortness of breath, and chest pain.
The objective is to build a machine learning model—specifically using the Decision Tree algorithm—based on the given dataset, in order to predict whether a person is likely to have lung cancer in the future.
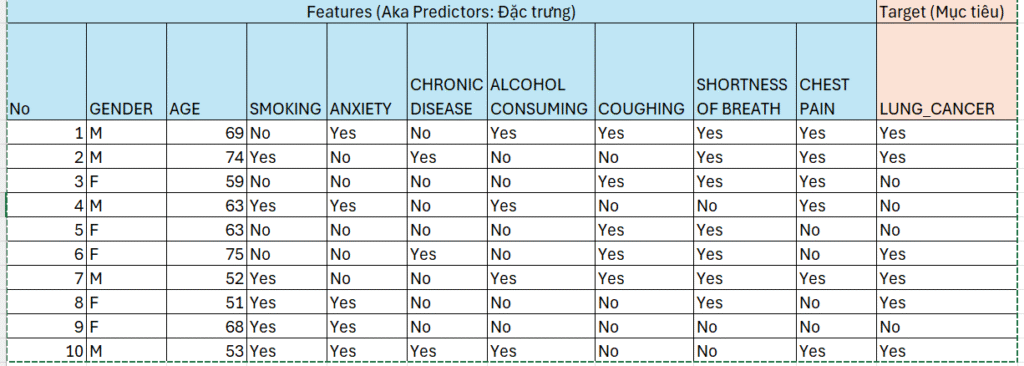
Before we begin learning how to build classification rules using a Decision Tree, let’s first consider what it would be like to build them using rule-based analysis.
Imagine you’re a doctor making a quick assessment of a patient’s risk of disease. You might first check if they are over 50, as older patients have a higher risk. Then, you might look for symptoms like shortness of breath, which also indicates a greater likelihood of illness. And what’s next? In some cases, if your confidence in the prediction is high enough, you might stop after just using these two features and their conditions. In other cases, you might need to continue the process—adding more features and repeating the evaluation—until you can confidently conclude whether the patient is at high risk of lung cancer.
=> At this point, we can see key issues with rule-based models: how to select the most important features along with their classification conditions, and how to determine whether the model will make accurate predictions when applied to patients with different combinations of symptoms in the future.